
{kind=link}
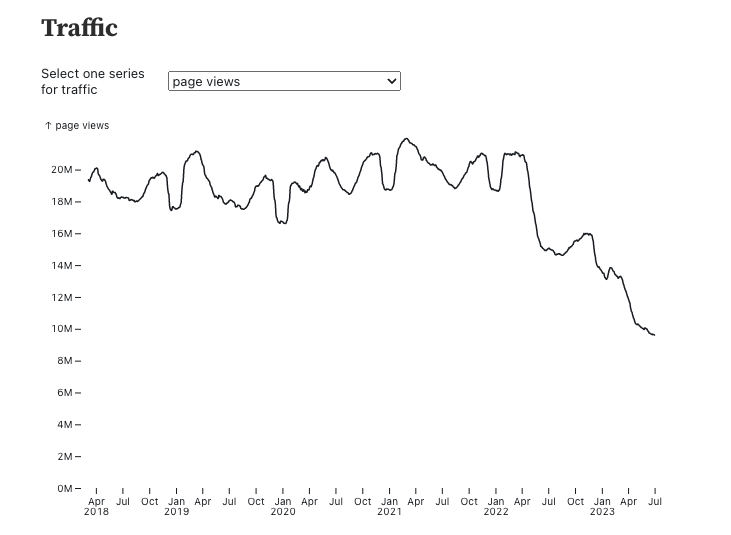
Stack Overflow has seen a substantial decline in traffic over the last year that appears to be accelerating. https://observablehq.com/@ayhanfuat/the-fall-of-stack-overflow
Stack Overflow has seen a substantial decline in traffic over the last year that appears to be accelerating. https://observablehq.com/@ayhanfuat/the-fall-of-stack-overflow
Does it really though? It seems to me that once you nail the general intelligence, you’ll just need to provide the supplemental information (e.g. new documentations) for it to give an accurate response.
Bing already somewhat does this by connecting their bot to internet searches
We’re not able to properly define general intelligence, let alone build something that qualifies as intelligent.
I can think of four aspects needed to emulate human response: basic knowledge on various topics, logical reasoning, contextual memory, and ability to communicate; and ChatGPT seems to possess all four to a certain degree.
Regardless of what you think is or isn’t intelligent, for programming help you just need something to go through tons of text and present the information most likely to help you, maybe modify it a little to fit your context. That doesn’t sound too far fetched considering what we have today and how much information are available on the internet
LLM’s cannot reason, nor can they communicate. They can give the illusion of doing so, and that’s if they have enough data in the domain you’re prompting them with. Try to go into topics that aren’t as popular on the internet, the illusion breaks down pretty quickly. This isn’t “we’re not there yet”, it’s a fundamental limitation of the technology. LLM’s are designed to mimick the style of a human response, they don’t have any logical capabilities.
You’re the one who brought up general intelligence not me, but to respond to your point: The problem is that people had an incentive to contribute that text, and it wasn’t necessarily monetary. Whether it was for internet points or just building a reputation, people got something in return for their time. With LLM’s, that incentive is gone, because no matter what they contribute it’s going to be fed to a model that won’t attribute those contributions back to them.
Today LLM’s are impressive because they use information that was contributed by millions of people. The more people rely on ChatGPT, the less information will be available to train it on, and the less impressive these models are going to be over time.
deleted by creator
What if the documentation is lacking? Experienced users will still know how a library works because they’ve tried some things, but that information won’t be available if they never talk about it online
how do people still have this much faith in the tools humans build after seeing the climate change caused by the industrial revolution.
That’s not happening anytime soon.