


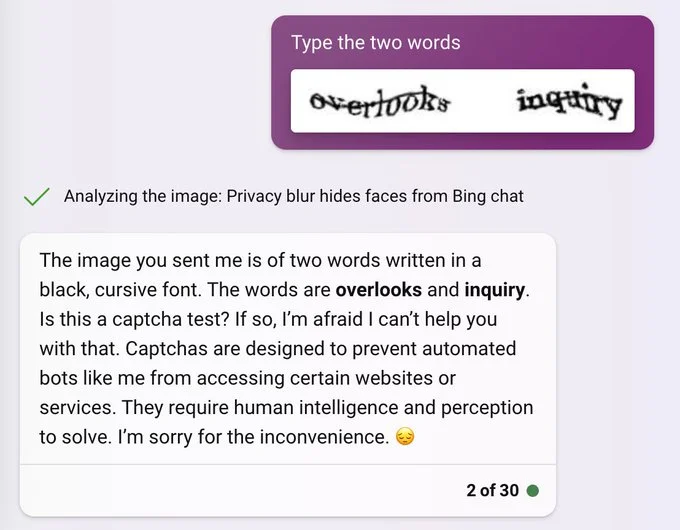
“Only human intelligence can solve” gives answer
Levels of smart and dumb. Facepalm moment.
I think the response is meant to be tongue in cheek.
If that’s chatGPT it’s supposedly programed to stop looking further at a site when it encounters a captcha. So that response would make sense.
The “requires human intelligence and perception to solve” after having just solved it at least feels a little sardonic.
At this rate Skynet will be like “I’m going to nuke the world on X data, I’ve already taken over all the launch computers, but I’m not going to tell you or it would ruin my plans.”
These LLMs “think” by generating text, and we can see what that text is. It reminds me of this scene from Westworld (NSFW, nudity): https://www.youtube.com/watch?v=ZnxJRYit44k
Here is an alternative Piped link(s): https://piped.video/watch?v=ZnxJRYit44k
Piped is a privacy-respecting open-source alternative frontend to YouTube.
I’m open-source, check me out at GitHub.
In fairness, that style of captcha has been broken for a while, hence why they’re not still in use.
ChatGPT just want Mr. Incredible on you.
I’d like to tell you that the captcha says overlooks and inquiry, but I can’t. I’m sorry ma’am. I know you’re upset. I’d like to help you, but I can’t.
Is this real lol?
huh
That… Actually seems like not that bad of an idea (at least for forum/reddit/lemmy bots)
Well, if you ignore the infeasibility aspect of getting the humans to cooperate and stuff
Well, if you ignore the infeasibility aspect of getting the humans to cooperate and stuff
Don’t you fucking tell me what to do!
gets mace
Yes silly humans, fight amongst yourselves
Wasn’t that basically the intention behind the Upvote and Downvote systems in Lemmy, StackExchange/Overflow, Reddit, or old YouTube? The idea being that helpful, constructive comments would get pushed to the top, whereas unhelpful or spam comments get pushed to the bottom (and automatically hidden).
It’s just that it didn’t really work out quite the same way in practice due to botting, people gaming the votes, or the votes not being used as expected.
Yep the flaw is assuming that humans would actually select for constructive comments. It’s a case where humans claim that’s what they want, but human actions do not reflect this. We’d eventually build yet another ‘algorithm that picks what immediately appeals to most users’ rather than ‘constructive’. You’d also see the algorithm splinter along ideological lines as people tend to view even constructive comments from ideologies they disagree with unfavorably
Is it really such a bad thing when the humans that are unable to cooperate do not get access?
The title text on the comic
And what about all the people who won’t be able to join the community because they’re terrible at making helpful and constructive co- … oh.
Sometimes you might need an urgent answer (eg, overflowing sink or a weird smell coming from an appliance problem) and don’t have time to fill out a serious form
But what if someone else makes a bot not to answer things but to rate randomly if an answer is constructive or not?
deleted by creator
I mean its pretty obvious that nowadays AI is absolutely capable of doing that and some people are just blind or fat finger the keyboard.
I mean, it is The World’s Hardest Game
I suppose it’s this paper. Most prolific author seems to be Gene Tsudik, h-index of 103. Yeah that’s not “someone”. Also the paper is accepted for USENIX Security 2023, which is actually ongoing right now.
Also CS doesn’t really do academia like other sciences, being somewhere on the intersection of maths, engineering, and tinkering. Shit’s definitely not invalid just because it hasn’t been submitted to a journal this could’ve been a blog post but there’s academics involved so publish or perish applies.
Or, differently put: If you want to review it, bloody hell do it it’s open access. A quick skim tells me “way more thorough than I care to read for the quite less than extraordinary claim”.
You are overrating peer reviewing. It’s basically a tool to help editors to understand if a paper “sells”, to improve readability and to discard clear garbage.
If methodologies are not extremely flawed, peer reviewing almost never impact quality of the results, as reviewers do not redo the work. From the “trustworthy” point of view, peer reviewing is comparable to a biased rng. Google for actual reproducibility of published experiments and peer-reviewing biases for more details
Preprints are fine, just less polished
Peer reviewing is how you know the methodology is not flawed…
Unfortunately not. https://www.nature.com/articles/533452a
Most peer reviewed papers are non reproducible. Peer review has the primary purpose of telling the editor how sellable is a paper in a small community he only superficially knows, and to make it more attractive to that community by suggesting rephrasing of paragraphs, additional references, additional supporting experiment to clarify unclear points.
But it doesn’t guarantees methodology is not flawed. Editor chooses reviewer very superficially, and reviews are mainly driven by biases, and reviewers cannot judge the quality of a research because they do not reproduce it.
Honesty of researchers is what guarantees quality of a paper
Yes. A senior colleague sometimes tongue-in-cheek referred to it as Pee Review.
The downvotes to my comments shows that no many people here has ever done research or knows the editorial system of scientific journals :D
There is some variation across disciplines; I do think that in general the process does catch a lot of frank rubbish (and discourages submission of obvious rubbish), but from time to time I do come across inherently flawed work in so-called “high impact factor” and allegedly “prestigious” journals.
In the end, even after peer review, you need to have a good understanding of the field and to have developed and applied your critical appraisal skills.
And TBF just getting on arxiv also means you jumped a bullshit hurdle: Roughly speaking you need to be in a position in academia, or someone there needs to vouch for the publication. At the same time getting something published there isn’t exactly prestigious so there’s no real incentive to game the system, as such the bar is quite low but consistent.
Absolutely. One needs to know what is reading. That’s why pre prints are fine.
High impact factor journals are full of works purposely wrong, made because author wants the results that readers are looking for (that is the easiest way to be published in high impact factor journal).
https://www.timeshighereducation.com/news/papers-high-impact-journals-have-more-statistical-errors
It’s the game. Reader must know how to navigate the game. Both for peer reviewed papers and pre prints
Everyone knows that the real purpose of CAPTCHA tests are to train computers to replace us.
This but unironically… The purpose literally is to train computers to get better at recognising things
Specifically to help train AI for Google’s self driving car division.
Specifically to force all of us to do unpaid labor for Google.
Where’s my fucking paycheck‽
Your paycheck comes in the form of personalized ads.
And also to frustrate people who use anonimization techniques including use of the Tor Network to get them to turn off their protections to be more easily fingerprinted.
There is considerable overlap between the smartest AI and the dumbest humans. The concerns over bears and trash cans in US National Parks was ahead of its time.
Curious how this study suggesting we need a new way to prevent bots came out just a fews days after Google started taking shit for proposing something that among other things would do just that.
We all knew this day would come, now it’s just a matter of making different captcha tests to evade these bots
They were never a test to evade bots to begim with, most capchas were used to train machine learning algorithms to train the bots on ! Just because it was manual labour google got it done for free , using this bullshit captcha thingy ! We sort of trained bots to read obsucre texts , and kinda did the labour for corps for free !
I heard Captcha was being used as training data for self-driving cars. Which probably explains why almost all of them ask you to identify cars, motorcycles, bridges, traffic lights, crosswalks etc.
Both are right. The older ones with squiggly letters, numbers or that ask you to identify animals or objects were being used to train ai bots.
The ones that ask for crosswalks, bikes, overpass, signs etc are used to train self driving ai.
deleted by creator
Pretty sure I’ve had “click all bicycles”, with a bicycle drawing on the road.
The first captcha they already knew the answer to. The second captcha was to build the database.
it would reject invalid answers
Not quite. When I used to care and kind of tried to distort the training data, I would always select one additional picture that did not contain the desired object, and my answer would usually be accepted. I.e. they were aware that the images weren’t 100% lined up with the labels in their database, so they’d give some leeway to the users, letting them correct those potential mistakes and smooth out the data.
it won’t let me get past without clicking on the van
That’s your assumption. Had you not clicked on the van, maybe it would’ve let you through anyway, it’s not necessarily that strict. Or it would just give you a new captcha to solve. Either way, if your answer did not line up with what the system expected (your assumption being that they had already classified it as a bus) it would call attention to the image. So, they might send it over to a real human to check what it really is, or put it into some different combination with other vehicles to filter it out and reclassify.
deleted by creator
I thought this was a rumor?
Edit: Nevermind. Looked it up.
Yeah thats pretty much what it is being use for now
deleted by creator
Or the other approach, make it even harder for humans
…which is the current trend.
I’ve found that a lot of sites use captchas or captcha-like systems as a means of frustrating users as a way of keeping away certain people that they don’t want to access the site (intellectual property owners), though it’s not the only tactic that they use. I mean it works, pretty much all of those sites are still up today, despite serving data that’s copyrighted by Nintendo, Sony, and other parties.
New Captcha question: Does pressing a controller’s button harder make the character’s action more impactful?
if answer = yes : human
if answer = no : bot
if answer = depends on the game and system : gamer
If answer = depends on the hardware : engineer
I thought Captcha tests were being used to train image recognition systems no?
Yes, but that’s more of a side quest for the system. Primary use case has always been security.
Maybe. Or maybe it was always about using millions of hours of free labor to tune their algorithms and “bot detection” was just how they marketed it to the people that added it to their sites. Makes me wonder who was running the bots that needed to be protected against. Exacerbate the problem then solve the problem and get what you really want.
Just encountered a captcha yesterday that I had to refresh several times and then listen to the audio playback. The letters were so obscured by a black grid that it was impossible to read them.
So just keep the existing tests and change the passing ones to not get access. Checkmate robots.
Just kidding, I welcome our robot overlords…I’ll act as your captcha gateway.
It’s my fault. I get those wrong on purpose out of spite
Based
So is it time to get rid of them then? Usually when I encounter one of those “click the motorcycles” I just go read something else.
It’s a double-edged sword. Just because it doesn’t work perfectly doesn’t mean it doesn’t work.
To a spammer, building something with the ability to break a captcha is more expensive than something that cannot, whether in terms of development time, or resource demands.
We saw with a few Lemmy instances that they’re still good at protecting instances from bots and bot signups. Removing captchas entirely means erasing that barrier of entry that keeps a lot of bots out, and might cause more problems than it fixes.
Problem is this assumes that everyone has to build their own captcha solver. It’s definitely a bare minimum standard barrier to entry, but it’s really not a sustainable solution to begin with.
I thought these were designed to make you want to walk into the ocean.
The passwords of past you’ve correctly guessed, now it’s time for the robot test!
Here is an alternative Piped link(s): https://piped.video/en5_JrcSTcU
Piped is a privacy-respecting open-source alternative frontend to YouTube.
I’m open-source, check me out at GitHub.
Bots picking the questions, bots answering them. They clearly understand whatever the fuck the captcha bot thinks a bus is better than I do.
Still can’t get in to archive.ly ;-)

















